|
|
如果连这些都没做,就不要抱怨缺数据了时间:2017-10-31 浏览量:1007 来源:Linklab 作者:数据库的创建需要整个科研团队的协作,大量科研经费的投入。数据库的使用更是每一位科研工作者日常工作的一部分。对于科研工作者,使用数据库的数据进行科学分析,形成科研想法并得到科研结果;对于创建数据库的团队,使用数据库则更多的是如何将数据库维护好并与外部合作者进行项目合作。 今天,我想跟大家分享:作为科研工作者如何有效利用数据库的数据?
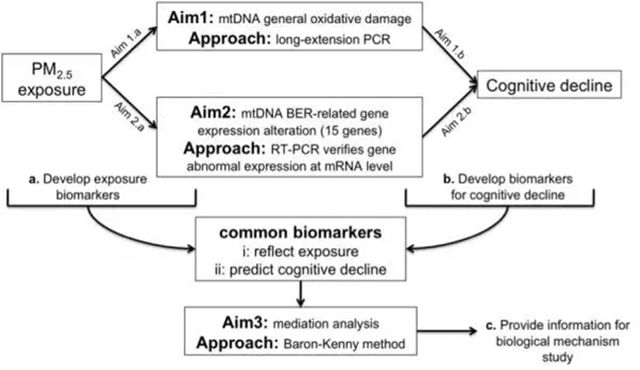
数据库的使用必须要有一定的目的,无目的的使用数据库就像姜太公钓鱼,也许运气能带来一点成果吧。 根据分析角度,大致可以分为如下四类: 1.横断面分析:用来描述数据库内病人的特征; 2. Association(相关性分析):相关性的研究可为临床和生物实验做好“知道”作用,post-marketing的随访研究可为药物副作用和长期效应提供依据; 3. Mechanism(机理研究):数据库合并检测血液、活检或粪便等生物标本获得实验室变量(包括生物标记物、代谢物、基因检测等),临床实验就可进行药理分析,帮助研究各疾病的发生、发展和进程的研究。 4. Prediction(疾病预测):基于以上研究,综合病人自报信息和生理病理检 验结果,就可以用于病人疾病预测以及行管政策的制定。 先举一个例子帮助理解 假设需要证明:mtDNA氧化损伤介导PM2.5暴露引起的认知下降。 利用如下逻辑图:
1. 横断面分析:可以报道数据库的PM2.5暴露的水平等 2. 相关性分析:可以分析PM2.5暴露与认知下降是否相关;如果相关则为进一步的机理研究提供证据; 3. 机理分析:利用生物样本检测指标mtDNA氧化损伤水平(mtDNA拷贝数),通过Baron-Kenny分析方法得到mtDNA氧化损伤水平是否为PM2.5暴露引起认知下降的机制之一; 4. 疾病预测分析:根据PM2.5暴露、认知下降和mtDNA氧化损伤水平,以及其他相关的风险因素获得认知下降的疾病预测模型。 基于这个例子,让我们细细讲讲各种分析方法吧。 横断面分析 横断面分析:选择一个时间点进行横断面分析,常常描述暴露因素或者疾病患病率和发病率。也可以延伸到描述患病率或发病率随时间的变化(WHO报告一般为这一类)。 横断面的研究局限性很大,而且对数据库的量有一定的要求。 相关性研究 临床试验数据库往往是基于相对周期较短的临床试验产生的数据,而临床试验后的长期随访则产生了长期观察所得的临床终点的结果,比如癌症、生存率等。 对于临床数据库,除了研究临床试验目的之外,往往还可以进行其他方面的分析。那么如何入手呢? 1. 从暴露因素角度挖掘数据。暴露因素往往包含如下几类: 1)环境因素,比如空气污染、水污染等; 2)工作、职位等社会因素,比如收入、社会地位等; 3)生活方式,比如饮食、锻炼、睡眠、心理压力、性生活等; 4)政策因素,全国各地政策各有不同,很多也影响着健康状况。 这些暴露因素往往被忽略,但时刻影响着长期健康状况。因此,可以试着看看这些因素与健康指数的关联性,也许会有新发现呢! 2. 从临床终点角度挖掘数据: 1) 短期临床终点:CVD、糖尿病、肥胖、COPD等; 2) 长期临床终点:肿瘤、死亡等; 3)生活质量评价: 尤其对于以病人为样本的临床试验,完全可以寻找临床用药治疗/治疗与生活质量的关系。 一个研究一般只挑选一项关键的结局终点事件作为主要测量指标,而其他多项指标作为次要测量指标。对于结局指标的关键是一定要明确定义终点,并且测量方法和测量的时间都需要规范化,这也是发文章时审核的重点之一。除非研究有特殊需要,一般不采用生化检查结果等“中间结局”指标;最好还能是由第三方来认证的。 对于相关性分析,对数据库的要求:1)baseline和随访信息较为全面;2)对于相关变量收集较为正确和全面;3)对于病人自报变量没有太大偏差;4)没有太多数据丢失的情况(理论上来说10%的missing data将足以影响分析结果)。满足了这些条件,建立的相关性将比较有说服力。
如果数据库内包含生物样本信息,则可以进行研究使用药物/临床干预与机体(含病原体)相互作用及其规律和作用机理。基因组学,表观基因组学和代谢物组学都包含在这类分析中。 机理研究可以很好的应用于药物和治疗方法的选择。可以利用的生物样本包括:血液、粪便、活检、指甲、头发、唾液等,或用于检测暴露物的浓度或代谢物浓度、微生物、病例组织特征、基因检测信息等。通过实验室检测,获得实验室数据用于分析相关性内的生物学机制。 对数据库的要求除了满足以上相关性分析中提到的要求外,还需要具备:1) 生物样本收集;2)生物标记物的实验室检测和验证。 疾病预测分析 通过相关性分析和机理分析,就可以构建疾病的预测模型。疾病预测模型往往提示患者暴露因素与健康指标间的关联,提示健康风险。1)预测疾病风险;2)提示政府部门相关的防御措施;3)帮助病人改变不良生活习惯;4)促进更多的临床研究推进健康发展。 为了做好一个疾病预测模型,需要有相关疾病信息,暴露信息,生物样本检测信息,及混淆因素的信息,共同形成一个健康预测模型。 从数据库的标准,到数据库的构建,再到数据库数据的使用,基本上我们完成了框架性的介绍。未来两期,我们将通过一个例子真实展示对于一个数据库的思考。至于数据库平台的使用,也即将呈现给大家。谢谢您的关注,期待我们哦!
|
急救电话:0813-120 预约电话:0813-2401126、0813-2401026 投诉电话:2300337 联系电话(传真):0813-2202665 电子邮箱:zg_120@126.com
檀木林院区:四川省自贡市自流井区檀木林街19号 汇东院区:四川省自贡市自流井区丹桂大街400号
办公时间:上午8:00-12:00,下午14:30-17:30(周一至周五,节假日除外)
蜀ICP备13006683号-1Copyright © 2002-2024 四川省自贡市第四人民医院 自贡市急救中心 四川卫生康复职业学院附属医院 All Rights Reserved